前言
索引是由存储引擎实现的一种快速查找数据的结构,不同存储引擎对索引的实现和支持不同。其不仅能影响到select语句,也能影响到insert语句和drop语句。不仅能影响到查询的where部分,也能影响到select部分,group by部分以及order by部分.
在MySQL中,索引采用的数据结构一般是B+树。这种数据结构使得可以通过尽量少的读磁盘操作来找到数据在磁盘上的位置。由于B+树上的数据是有序的,所以合适的索引一定程度上能影响合适的含有order by的SQL语句的性能。可以通过查看explain语句输出的Extra列有无Using filesort来确定执行此SQL语句是否需要经过排序。如果有order by,但Extra列无Using filesort,则说明排序被索引优化了(不需要经过排序). 本文中的索引,如果未经特别说明,均指B+树索引.
聚簇索引
术语"聚簇"表示数据行和相邻的键值紧凑地存储在一起,因为无法将数据行存储在两个地方,所以一个表只能有至多一个聚簇索引。与此相对的是二级索引,此处二级指需要两次不同的索引查找(聚簇索引相当于一级索引)。在本文,聚簇索引指主键对应的索引,因为如果不这么定义,那么MyISAM存储引擎就不存在聚簇索引,而都是二级索引。
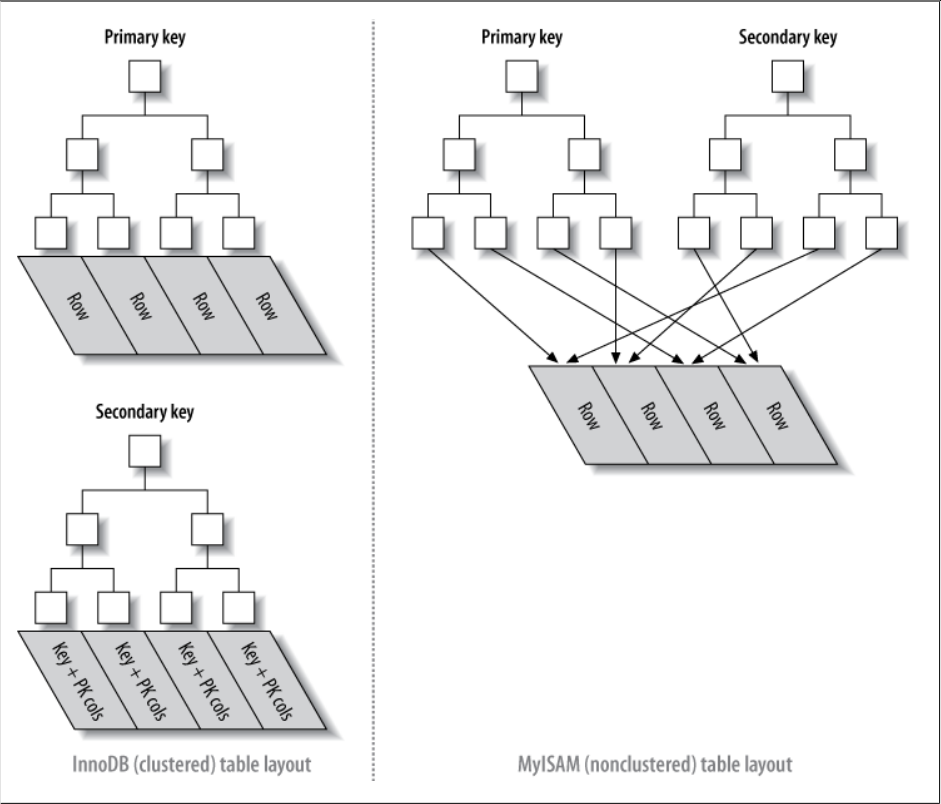
InnoDB
InnoDB将整张表存储在一个主键索引(B+树)上,即表是以B+树的形式存储的。所以InnoDB表必须有个主键(若未指定,会自动分配主键)。由于B+树是有序的,所以如果有order by PK这样的语句,存储引擎只需中序遍历一次整个B+树而无需额外的排序操作即可得到有序的结果。
InnoDB存储引擎的聚簇索引的一个劣势是插入速度依赖于插入顺序,按主键的顺序插入是最快的,否则,会引起B+树大量的分裂操作,也会使树上的节点不够紧凑,此时,可以使用OPTIMIZE TABLE命令重新组织一下数据表。因此,有人建议使所有InnoDB表的主键总是与行无关的单调递增的数字。
MyISAM
不同于InnoDB,MyISAM存储引擎将整张表存储在连续的磁盘空间。这使得MyISAM存储引擎存储的表可以不需要主键。数据是以插入的顺序依次存储。对于MyISAM,聚簇索引和二级索引没有任何差别,其B+树叶子节点都是包含指向行位置的指针。
二级索引
也称为辅助索引。听名字就知道,此索引不是必须的,只是起到辅助作用的一种索引。
InnoDB
InnoDB存储引擎的二级索引对应的B+树的非叶子节点大致和聚簇索引相同,不过叶子节点存储的值不是一个数据行,而是对应行的主键值(原因在于,当从B+树上插入 或删除节点时,指向一行的指针可能会修改,而这一行的主键不会被修改,除非修改了这一行的内容,而这相当于在一个事务插入一行新行和删除旧行)。所以使用InnoDB的二级索引需要查找两次索引树,一次查此二级索引的B+树找到数据行的主键值,第二次根据此主键值查找主键索引的B+树找到数据行的完整内容。不过也有一个例外,即使用覆盖索引。这时,由于索引覆盖了查询所使用的内容,直接在二级索引树上即可查到返回的所有数据。
MyISAM
对于MyISAM存储引擎来说,其二级索引和聚簇索引完全相同。
多列索引
多列索引,即多列联合构成的索引,适当的多列索引可以使得检索速度比只建立单列索引更快。但不适当的多列索引只会白白浪费空间。
多列索引的使用需满足几个条件:
- 对or无效。(所以语句中最好不用or而是使用union联合两个查询的结果);
- 左前缀匹配。这里最左前缀指的不是列在where子句中的顺序(因为where子句会经过优化而得到最好的顺序),而是指索引的最左前缀;
- 不可跳过索引中的列;
- 如果查询中有某个列是范围查询,则其右边的所有列都无法使用索引优化查找;
假设表有a,b,c三列,有个联合索引(a,b,c),那么下面的查询可以使用多列索引:
- a=1 and b=“2” and c=3;完全使用索引;
- a=1 and b=“2”;只使用了前缀a, b;
- a=1 and c=3;只使用了前缀a;
- a>1 and a<3 and b=“2” and c=3;只使用了前缀a,规则4;
- a in (1, 2) and b=“2” and c=3;完全使用索引,a的数量有限,不算范围;
- a=1 and b like ‘2%’ and c=3;只使用了前缀a,b,规则4;
覆盖索引
指索引能覆盖查询所使用的列。对一个查询使用explain语句,如果返回的Extra列含有Using index,即表示此查询使用了覆盖索引。由于覆盖索引能覆盖查询使用的列,对于InnoDB存储引擎来说,这使得不需要额外的查询主键索引的B+树,这会极大地提升查询的性能。
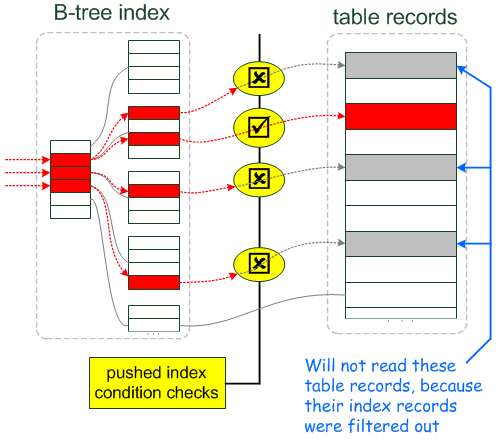
ICP(index condition pushdown)
ICP, aka index condition pushdown, 索引条件下推,适用于MySQL5.6+。对一个查询使用explain语句,如果返回的Extra列中含有Using index condition,即表示此查询使用了ICP。在说ICP之前,得先说明一个基本概念,即where子句的解析结果。其大致会被解析为如下三部分:
- 索引的范围(index range);索引范围的确定参考多列索引部分。
- 还能用索引过滤的条件(index condition);
- 不能用索引过滤的条件(where);
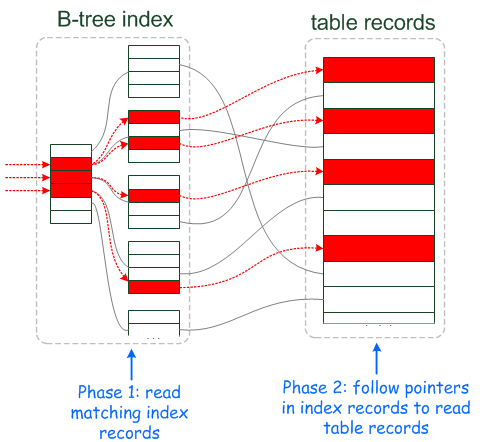
在MySQL 5.6之前,2和3是不作区分的。服务器在收到查询语句后,会根据表含有的索引及查询的where子句确定索引的范围(即1),并将其发给存储引擎,存储引擎返回在这些范围内的行,将其返回给MySQL服务器,MySQL服务器再使用2,3来对返回的行进行过滤,最后将得到的结果返回MySQL客户端。有一点需要说明的是,InnoDB使用的B+树的叶子节点是连着的,所以确定范围后可以很快遍历得到在这一范围内的所有行。
在MySQL 5.6+中,引入了ICP,即将索引条件下推给存储引擎,这会使得存储引擎筛选得到的行的数目大大减小,从而在一定情况下大大提升查询的性能。ICP就是"将索引条件下推到存储引擎"的意思。
额外
- 索引越长,性能越差。道理很简单,B+树上 每个节点差不多相当于磁盘上一个页,页大小固定,当索引越长,一页上能存储的键越少,需读取的页更多。
- B+树而不是B树?B+树只在叶子节点存储值(行),B树在每个节点都存储值,而由于页的大小固定,使用B+树使得每个页能存储的键更多,搜索得更快。
- where子句的各部分顺序不影响实际执行速度。
参考资料
- «高性能MySQL» 第三版
- MySQL 官方文档
- MariaDB 关于ICP的描述
- 何登成的博客